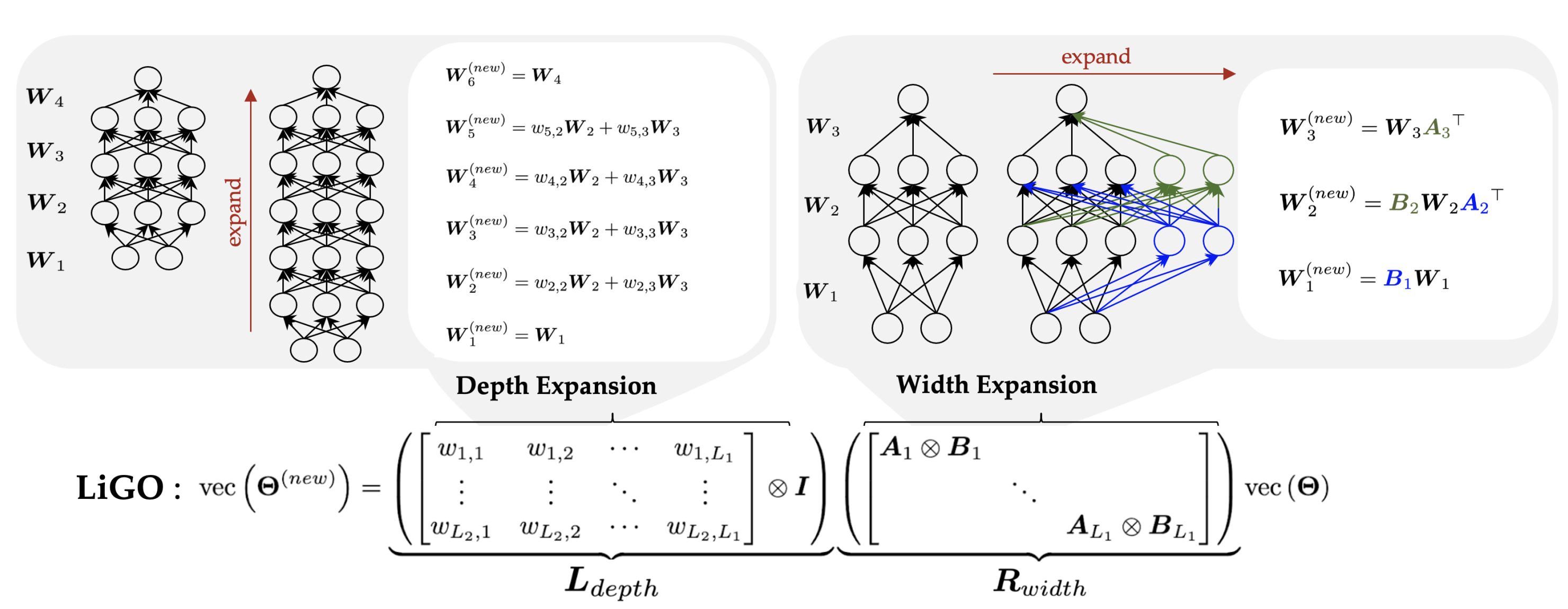
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
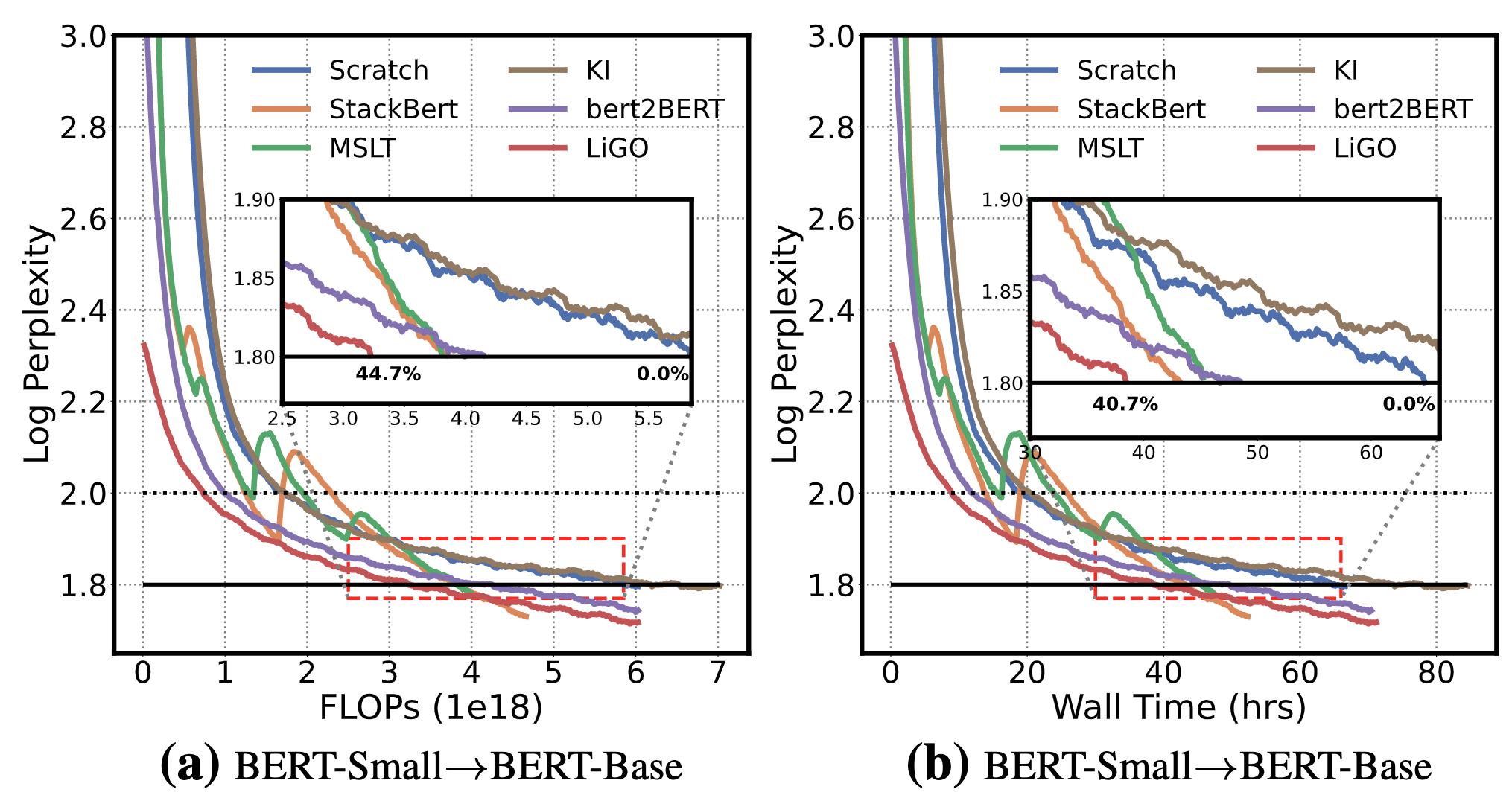 |
|
|
Peihao Wang, Rameswar Panda, Lucas Torroba Hennigen, Philip Greengard, Leonid Karlinsky, Rogerio Feris, David Cox, Atlas Wang, Yoon Kim Learning to Grow Pretrained Models for Efficient Transformer Training International Conference on Learning Representations (ICLR), 2023 [PDF] [Code] |