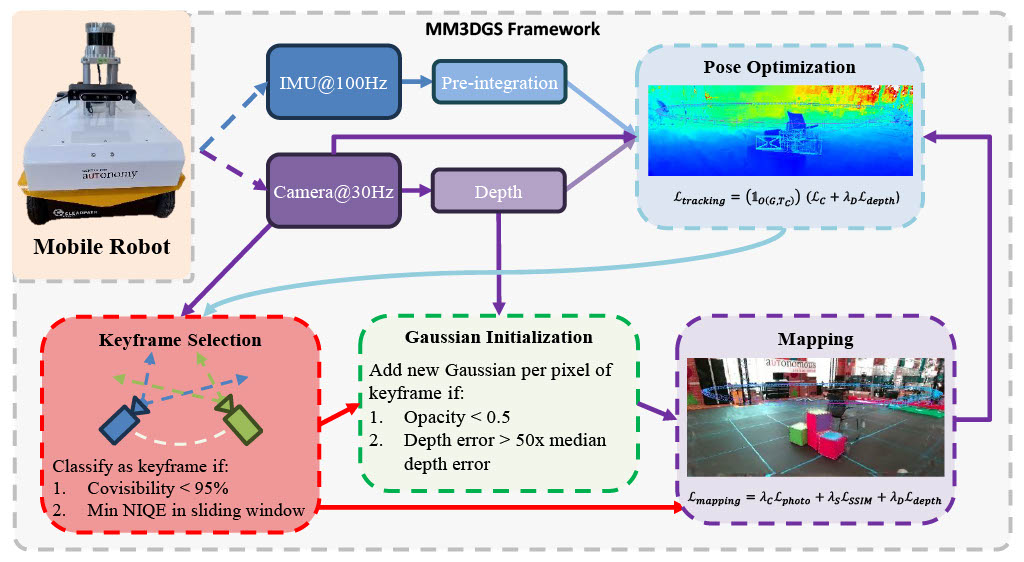
Simultaneous localization and mapping is essential for position tracking and scene understanding.
3D Gaussian-based map representations enable photorealistic reconstruction and real-time rendering
of scenes using multiple posed cameras. We show for the first time that using 3D Gaussians for map
representation with unposed camera images and inertial measurements can enable accurate SLAM.
Our method, MM3DGS, addresses the limitations of prior neural radiance field-based representations by
enabling faster rendering, scale awareness, and improved trajectory tracking. Our framework enables
keyframe-based mapping and tracking utilizing loss functions that incorporate relative pose transformations
from pre-integrated inertial measurements, depth estimates, and measures of photometric rendering quality.
We also release a multi-modal dataset, UT-MM, collected from a mobile robot equipped with a camera
and an inertial measurement unit. Experimental evaluation on several scenes from the dataset shows
that MM3DGS achieves 3x improvement in tracking and 5% improvement in photometric rendering quality
compared to the current 3DGS SLAM state-of-the-art, while allowing real-time rendering of a high-resolution dense 3D map.